TinyMT vs. SFMT
In the birdnest simulator, I've used TinyMT as a uniform random number generator. My reasons are simply familiarity and the source's portability. However, I started looking into faster PRNGs to work with much larger simulations. I decided to switch to SFMT after reading their benchmarks. Pulling in their sources, I speed-tested the difference between both PRNGs. The results proved quite interesting.
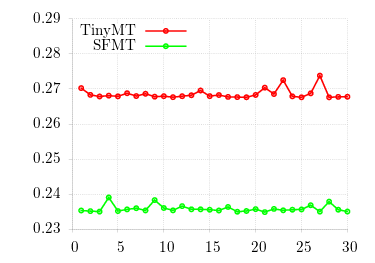
I wasn't impressed: this is on average only a 12% speedup, and the literature seemed to promise much more.
The method I used was simple: replace all invocations of tinymt32_generate_uint32() and
tinymt32_generate_float() with sfmt_generate_uint32() and sfmt_genrand_real2().
However, I noticed that, when benchmarking this directly against the SFMT calls, this was quite slow. Why should that be? After all, I was invoking the random generator as follows:
#define random_unit(_p) sfmt_genrand_real2((sfmt_t *)(_p))
This somehow led to a 1.85-fold increase in raw benchmarks directly against sfmt_genrand_real2().
Why?
The difference, I realised, was that the sfmt_t value passed to the RNG was created on
the heap with malloc().
The reason for this isn't quite clear to me, and I don't have time to research the matter fully, but as it's not alignment (my test machine, a Mac OS X, guarantees
that malloc() is SSE-aligned), I assume it's locality.
By making all sfmt_t variables be on the stack, I removed this overhead.
Did it make a difference?
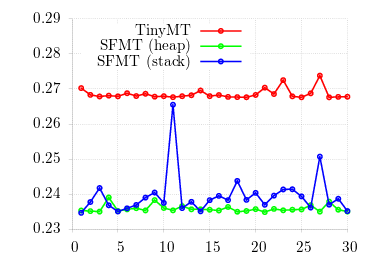
sfmt_t variable on the stack versus on the heap.
No — at least not for this benchmark. Although a raw test (using SFMT's own test framework) showed parity, this graph really shows us is that the Poisson implementation doesn't depend enough on the uniform PRNG to matter. (The graph jittering is because SFMT uses SSE, which is also used by the test machine's in-use graphic interface.) Let's see if we can demonstrate run-time by looking at the entire birdnest system, which draws uniform random numbers proportionate to the Poisson random numbers.
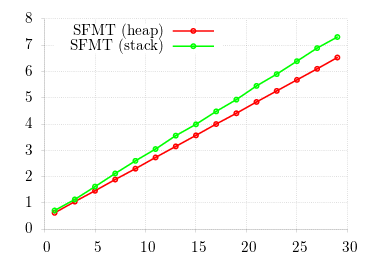
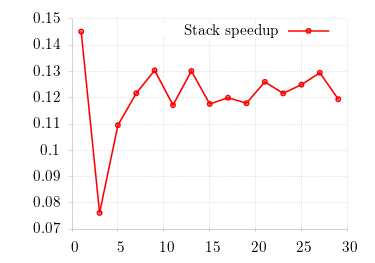
In this graphs, the x-axis λ represents the payoff matrix maximum. The matrix is laid it out as A = {λ, λ + 4, λ + 4, λ}. Each data point is the time for one generation of 10 000 000 individuals on 1 000 000 islands with 0.75 migration probability, On the left-hand side, I show the raw speed; on the right-hand side, the fractional increase: about 12% speed-up of the stack over the heap version. Can we do even better?
No.
Although the SFMT documentation is correct in saying that generation by [sfmt_fill_array32] is much faster than the
following gen_rand function, converting these uint32_t into float numbers makes the extra speed all but meaningless.
In other words, consider the following block-fillled example (where I later printf("%g\n",
&check); to ensure that the conversion isn't optimised away):
sfmt_init_gen_rand(&v, seed);
sfmt_fill_array32(&v, buffer, BLOCK_SIZE);
for (j = i = 0; i < 1000000000; i++, j++) {
if (j == BLOCK_SIZE) {
sfmt_fill_array32(&v, buffer, BLOCK_SIZE);
j = 0;
}
check += sfmt_to_real2(buffer[j]);
}
This has no speed advantage over the following:
sfmt_init_gen_rand(&v, seed); for (j = i = 0; i < 1000000000; i++, j++) check += sfmt_genrand_real2(&v);
In fact, the latter is slightly faster because the j == BLOCK_SIZE conditional is not
within the codepath.
Since most of our PRNG invocations are for floating-point numbers in the unit interval, we gain little but lose simplicity by
using the block example.
However, the Poisson implementation does use direct uint32_t numbers.
Can we increase performance by using a different PRNG method for Poisson random variable generation?
Also no.
Although the uint32_t generation code, replacing sfmt_genrand_uint32() in our example above, is about half as fast as block-filling and using the uint32_t values from the buffer, the Poisson implementation has a conditional within
the tight loop using these values:
for (;;) {
r = sfmt_genrand_uint32(arg);
if (r >= min)
break;
}
The penalty of this conditional nullifies the benefit of using a block-fill algorithm, leaving the real processing time of both methods virtually identical. This can be cross-checked by introducing a conditional into both versions of the above test as follows:
sfmt_init_gen_rand(&v, seed); for (j = i = 0; i < 1000000000; i++, j++) check += sfmt_genrand_real2(&v) % 2 ? 2 : 1;
This and the block-fill algorithm have no effective run-time speed differences.